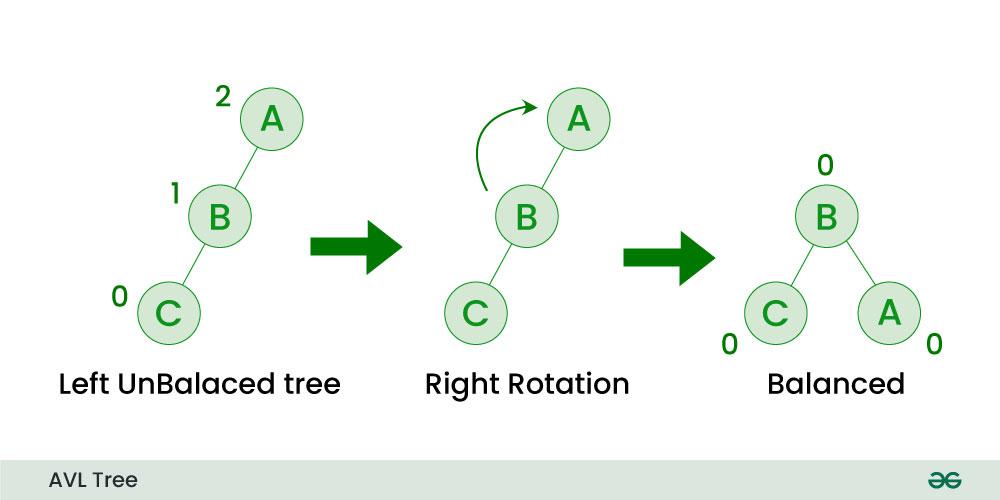
1. CTDL Cây
Cấu trúc dữ liệu cây biểu diễn các nút (node) được kết nối bởi các cạnh. Chúng ta sẽ tìm hiểu về Cây nhị phân (Binary Tree), Cây tìm kiếm nhị phân (Binary Search Tree) và Cây AVL trong bài viết này.
Cây nhị phân là một cấu trúc dữ liệu đặc biệt được sử dụng cho mục đích lưu trữ dữ liệu. Một cây nhị phân có một điều kiện đặc biệt là mỗi nút có thể có tối đa hai nút con. Một cây nhị phân tận dụng lợi thế của hai kiểu cấu trúc dữ liệu: một mảng đã sắp thứ tự và một danh sách liên kết (Linked List), do đó việc tìm kiếm sẽ nhanh như trong mảng đã sắp thứ tự và các thao tác chèn và xóa cũng sẽ nhanh bằng trong Linked List.
1.1 Khái niệm
Một số khái niệm quan trọng liên quan đến cây nhị phân:
- Đường: là một dãy các nút cùng với các cạnh của một cây.
- Nút gốc (Root): nút trên cùng của cây được gọi là nút gốc. Một cây sẽ chỉ có một nút gốc và một đường xuất phát từ nút gốc tới bất kỳ nút nào khác. Nút gốc là nút duy nhất không có bất kỳ nút cha nào.
- Nút cha: bất kỳ nút nào ngoại trừ nút gốc mà có một cạnh hướng lên một nút khác thì được gọi là nút cha.
- Nút con: nút ở dưới một nút đã cho được kết nối bởi cạnh dưới của nó được gọi là nút con của nút đó.
- Nút lá: nút mà không có bất kỳ nút con nào thì được gọi là nút lá.
- Cây con: cây con biểu diễn các con của một nút.
- Truy cập: kiểm tra giá trị của một nút khi điều khiển là đang trên một nút đó.
- Duyệt: duyệt qua các nút theo một thứ tự nào đó.
- Bậc: bậc của một nút biểu diễn số con của một nút. Nếu nút gốc có bậc là 0, thì nút con tiếp theo sẽ có bậc là 1, và nút cháu của nó sẽ có bậc là 2, …
- Khóa (Key): biểu diễn một giá trị của một nút dựa trên những gì mà một thao tác tìm kiếm thực hiện trên nút.
2. Cây tìm kiếm nhị phân
Cây tìm kiếm nhị phân biểu diễn một hành vi đặc biệt. Con bên trái của một nút phải có giá trị nhỏ hơn giá trị của nút cha (của nút con này) và con bên phải của nút phải có giá trị lớn hơn giá trị của nút cha (của nút con này).
Khai báo một node trong của cây:
struct Node {
int key;
Node* left;
Node* right;
};2.1 Thêm phần tử
Các hoạt động thêm sửa xóa cũng tương tự như linker list. Để thêm phần tử vào cây nhị phân tìm kiếm ta làm như sau:
- Nếu cây đang rỗng, thì chọn luôn phần tử thêm vào làm node gốc.
- Nếu cây khác rỗng:
- Nếu data của node lớn hơn phần tử thêm vào, thì gọi hàm đệ quy để thêm phần tử đó và node left và ngược lại.
Node* newNode(int data){
Node* node = new Node;
node->key = data;
node->left = nullptr;
node->right = nullptr;
return node;
}
Node* insertNode(Node* root, int data){
if (root == nullptr) return newNode(data);
if (data <= root->key) root->left = insertNode(root->left, data);
else root->right = insertNode(root->right, data);
}2.2 Duyệt cây
Duyệt cây là một tiến trình để truy cập tất cả các nút của một cây và cũng có thể in các giá trị của các nút này. Bởi vì tất cả các nút được kết nối thông qua các cạnh (hoặc các link), nên chúng ta luôn luôn bắt đầu truy cập từ nút gốc. Do đó, chúng ta không thể truy cập ngẫu nhiên bất kỳ nút nào trong cây. Có ba phương thức mà chúng ta có thể sử dụng để duyệt một cây:
- Duyệt tiền thứ tự (Pre-order Traversal)
- Duyệt trung thứ tự (In-order Traversal)
- Duyệt hậu thứ tự (Post-order Traversal)
2.2.1 Duyệt trung thứ tự
Nếu một cây nhị phân được duyệt trung thứ tự, kết quả tạo ra sẽ là các giá trị khóa được sắp xếp theo thứ tự tăng dần.
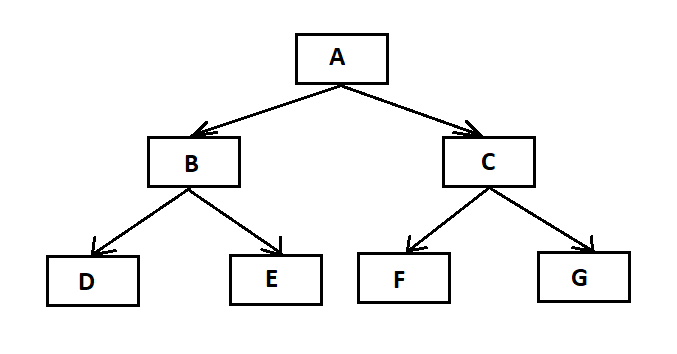
Ở hình ví dụ minh họa trên, A là nút gốc. Với phương thức duyệt trung thứ tự, chúng ta bắt đầu từ nút gốc A, di chuyển tới cây con bên trái B của nút gốc. Tại đây, B cũng được duyệt theo cách thức duyệt trung thứ tự. Và tiến trình tiếp tục cho đến khi tất cả các nút đã được truy cập. Kết quả của cách thức duyệt trung thứ tự cho cây trên sẽ là:
D → B → E → A → F → C → G
void LNR(Node* root){
if (root != nullptr){
LNR(root->left);
cout << root->key << " ";
LNR(root->right);
}
}2.2.2 Duyệt tiền thứ tự
Trong cách thức duyệt tiền thứ tự trong cây nhị phân, nút gốc được duyệt đầu tiên, sau đó sẽ duyệt cây con bên trái và cuối cùng sẽ duyệt cây con bên phải.
Ở hình ví dụ minh họa trên, A là nút gốc. Chúng ta bắt đầu từ A, và theo cách thức duyệt tiền thứ tự, đầu tiên chúng ta truy cập chính nút gốc A này và sau đó di chuyển tới nút con bên trái B của nó. B cũng được duyệt theo cách thức duyệt tiền thứ tự. Và tiến trình tiếp tục cho tới khi tất cả các nút đều đã được truy cập. Kết quả của cách thức duyệt tiền thứ tự cây này sẽ là:
A → B → D → E → C → F → G
void NLR(Node* root){
if (root != nullptr){
cout << root->key << " ";
NLR(root->left);
NLR(root->right);
}
}2.2.3 Duyệt hậu thứ tự
Trong cách thức duyệt hậu thứ tự trong cây nhị phân, nút gốc của cây sẽ được truy cập cuối cùng, do đó bạn cần chú ý. Đầu tiên, chúng ta duyệt cây con bên trái, sau đó sẽ duyệt cây con bên phải và cuối cùng là duyệt nút gốc.
Ở hình ví dụ minh họa trên, A là nút gốc. Chúng ta bắt đầu từ A, và theo cách duyệt hậu thứ tự, đầu tiên chúng ta truy cập cây con bên trái B. B cũng được duyệt theo cách thứ duyệt hậu thứ tự. Và tiến trình sẽ tiếp tục tới khi tất cả các nút đã được truy cập. Kết quả của cách thức duyệt hậu thứ tự của cây con trên sẽ là:
D → E → B → F → G → C → A
void LRN(Node* root){
if (root != nullptr){
LRN(root->left);
LRN(root->right);
cout << root->key << " ";
}
}3. Cây AVL
Hiệu suất trường hợp xấu nhất của cây tìm kiếm nhị phân (BST) gần với các giải thuật tìm kiếm tuyến tính, tức là Ο(n). Với dữ liệu thời gian thực, chúng ta không thể dự đoán mẫu dữ liệu và các tần số của nó. Vì thế, điều cần thiết phát sinh ở đây là để cân bằng cây tìm kiếm nhị phân đang tồn tại.
Cây AVL (viết tắt của tên các nhà phát minh Adelson, Velski và Landis) là cây tìm kiếm nhị phân có độ cân bằng cao. Các hành vi tìm kiếm, thêm hoặc xóa có độ phức tạp là O(log n) trong các trường hợp trung bình và trường hợp tệ nhất.
Node* newNode(int data){
Node* node = new Node;
node->key = data;
node->left = nullptr;
node->right = nullptr;
node->height = 1;
return node;
}3.1 Bậc và Balance Factor
Cây AVL kiểm tra độ cao (bậc) của các cây con bên trái và cây con bên phải và bảo đảm rằng hiệu số giữa chúng là không lớn hơn 1. Hiệu số này được gọi là Balance Factor (Nhân tố cân bằng).
BF(X) := Height(LeftSubtree(X)) - Height(RightSubtree(X)); abs(BF(X)) <= 1
Hình ảnh ví dụ của cây AVL:
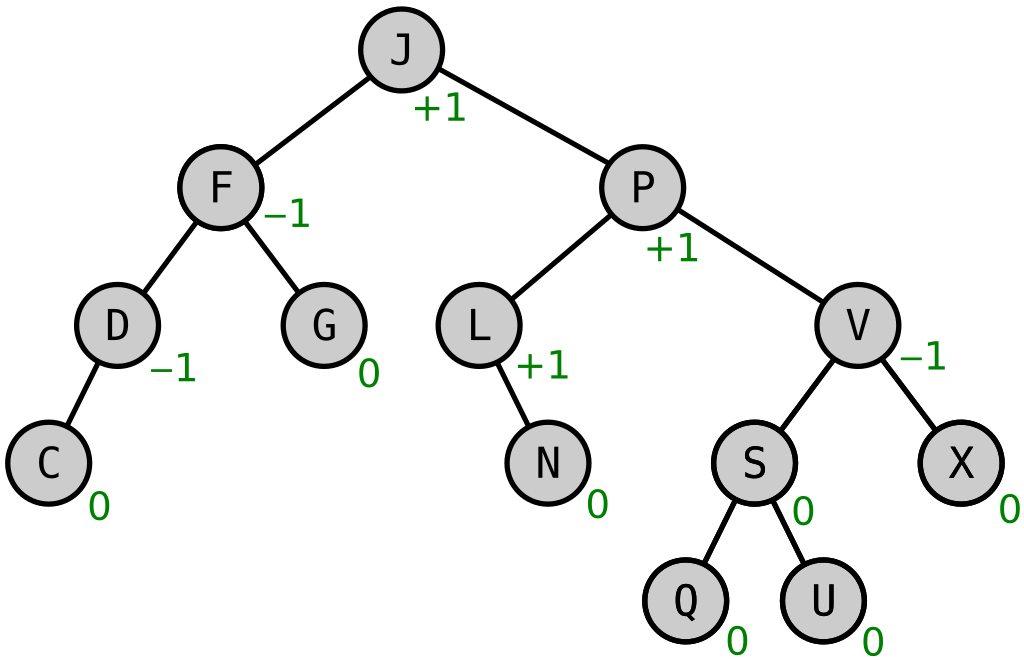
Chúng ta có 2 hàm phụ trợ để tính bậc của node và tính Balance Factor như sau:
int height(Node* node){
if (node == nullptr) return 0;
return node->height;
}
int getBalance(Node* node){
if (node == nullptr) return 0;
return height(node->left) - height(node->right);
}3.2 Xoay cây AVL
Với những cây nhị phân tìm kiếm, nhiều cây sẽ rơi vào trường hợp rất xấu, trường hợp xấu nhất là tất cả các node cha chỉ có một node con, việc tìm kiếm trên cây này có ĐPT là O(n), lúc đó cây này không khác biệt mấy so với một danh sách liên kết.
Để tránh trường hợp trên chúng ta phải biết những cách xoay cây ở trong cây nhị phân tìm kiếm.
3.2.1 Kĩ thuật xoay phải
Kỹ thuật này thường áp dụng cho những cây nhị phần tìm kiếm bị lệch về bên trái (độ cao của cây con trái lớn hơn độ của của cây con phải).
Node* rightRotate(Node* A){ // (B->C)<-A => B->(C<-A)
Node* B = A->left;
Node* C = B->right;
B->right = A;
A->left = C;
A->height = 1 + max(height(A->left), height(A->right));
B->height = 1 + max(height(B->left), height(B->right));
return B;
}3.2.2 Kĩ thuật xoay trái
Kỹ thuật này thường áp dụng cho những cây nhị phần tìm kiếm bị lệch về bên phải(độ cao của cây con phải lớn hơn độ của của cây con trái)
Node* leftRotate(Node* A){ // A->(C<-B) => (A->C)<-B
Node* B = A->right;
Node* C = B->left;
B->left = A;
A->right = C;
A->height = 1 + max(height(A->left), height(A->right));
B->height = 1 + max(height(B->left), height(B->right));
return B;
}3.3 Thêm node
Vì là cây AVL nên chúng ta sẽ không thêm các giá trị đã tồn tại trong cây.
Node* insertNode(Node* root, int data){
// a. insertNode like BST
if (root == nullptr) return newNode(data);
if (data < root->key) root->left = insertNode(root->left, data);
else if (data > root->key) root->right = insertNode(root->right, data);
else return root; // (do not add existing keys)
// b. update Height
root->height = 1 + max(height(root->left), height(root->right));
// c. get Balance factor
int balance = getBalance(root);
// Left Left case:
if (balance > 1 && getBalance(root->left) >= 0){
return rightRotate(root);
}
// Left Right case:
if (balance > 1 && getBalance(root->left) < 0){
root->left = leftRotate(root->left);
return rightRotate(root);
}
// Right Right case:
if (balance < -1 && getBalance(root->right) <= 0){
return leftRotate(root);
}
// Right Left case:
if (balance < -1 && getBalance(root->right) > 0){
root->right = rightRotate(root->right);
return leftRotate(root);
}
return root; // unchange root
}3.4 Tìm kiếm
Các bước tìm kiếm trong cây AVL giống như tìm trong BST.
Node* searchNode(Node* root, int data){
if (root == nullptr) return nullptr;
if (root->key == data) return root;
if (data < root->key) return searchNode(root->left, data);
else return searchNode(root->right, data);
}3.5 Xóa node
Node* minValueNode(Node* node){
Node* current = node;
while (current->left != nullptr){
current = current->left;
}
return current;
}
Node* deleteNode(Node* root, int data){
// a. deleteNode BST
if (root == nullptr) return root;
if (data < root->key) root->left = deleteNode(root->left, data);
else if (data > root->key) root->right = deleteNode(root->right, data);
else {
// no child or one child
if ((root->left == nullptr) || (root->right == nullptr)){
Node* temp = root->left ? root->left : root->right;
if (temp == nullptr){ // no child case
temp = root;
root = nullptr;
} else { // one child case
*root = *temp; // child -> root
}
delete temp;
} else { // two child
// get inorder successor
Node* temp = minValueNode(root->right);
root->key = temp->key; // swap value (root <-> inorder successor)
root->right = deleteNode(root->right, temp->key); // delete inorder successor
}
}
if (root == nullptr) return root;
// b. update height;
root->height = 1 + max(height(root->left), height(root->right));
// c. get Balance factor
int balance = getBalance(root);
// Left Left case:
if (balance > 1 && getBalance(root->left) >= 0){
return rightRotate(root);
}
// Left Right case:
if (balance > 1 && getBalance(root->left) < 0){
root->left = leftRotate(root->left);
return rightRotate(root);
}
// Right Right case:
if (balance < -1 && getBalance(root->right) <= 0){
return leftRotate(root);
}
// Right Left case:
if (balance < -1 && getBalance(root->right) > 0){
root->right = rightRotate(root->right);
return leftRotate(root);
}
return root;
}